【西瓜书】第十二章 计算学习理论
基础知识
计算学习理论是机器学习的理论基础,其目的是分析学习任务的困难本质,并根据分析结果指导算法设计.
Coursera上有一门很热门的台湾课程<机器学习基石>, 其上半部分都是在讲这部分内容, 足见其重要性.
我们给定数据集 $D={x,y}$, 假设所有样本$x \in \mathcal{X} y \in \mathcal{Y}$独立同分布,并服从分布$\mathcal{D}$.
$h$为$\mathcal{X \rightarrow Y}$的映射, 泛化误差为:
$h$在$D$上的经验误差为:
那么由于独立同分布, 经验误差的期望等于泛化误差, 学习理论非常关注的一个点在于经验误差的上限, 我们记作$\epsilon$ ,以及经验误差和泛化误差的逼近程度.
如果h在数据集D上经验误差为0, 则称二者一致, 否则称为不一致. 我们通过”不合”(disagreement)来度量两个映射之间的差别:
下面是一些在推导中经常用到的不等式:
- Jensen 不等式:
- Hoeffding不等式, 对$m$个随机变量$x_1, …, x_m$, $0\le x_i \le 1$, 则对任意$\epsilon \gt 0$
- McDiarmid不等式,对任意$1\le i\le m$,函数$f$满足:
则对任意$\epsilon \gt 0$ 有:
PAC学习
PAC理论(概率近似正确 Probably Approximately Correct)是学习理论中最基本的理论.
为了介绍该理论需要引入一些定义:
- $c$表示概念(concept), 表示样本空间到标记空间的映射, 若有对任何样例$(x,y)$有$C(x)=y$,则称$c$为目标概念, 所有目标概念的集合称为概念类$\mathcal{C}$
- $\mathcal{L}$为学习算法, 其能表示的所有可能概念的集合称为假设空间, 用$\mathcal{H}$表示. 由于$\mathcal{H},\mathcal{C}$通常不同, 所以对于$h\in \mathcal{H}$我们不确定其是否为目标概念,则称之为假设.
- 若假设空间存在至少一个目标概念, 则称该问题对算法$\mathcal{L}$可分,一致, 否则即为不可分,不一致.
那么显然, 我们希望学习算法学到的h尽可能接近c(准确学到c太难),换言之,我们希望以较大的概率学到误差满足预设上限的模型, 也就是”概率” “近似正确”的含义.
我们定义PAC辨识: 对$0\lt \epsilon$, $\delta \lt 1$, 所有$c\in \mathcal{C}$和分布$\mathcal{D}$, 若存在学习算法$\mathcal{L}$, 其输出的假设$h\in \mathcal{H}$ 满足:
因此我们可以得到有限假设空间都是PAC可学习的.
不可分情况
此时目标概念$c$不存在于假设空间中, 我们可以证明:
可以看出, 我们虽然没有办法学到目标概念,但是肯定可以学到一个泛化误差最小的假设, 如此,我们就将PAC学习推广到$c\notin \mathcal{H}$的情况, 也就是不可知学习.

VC维
但是现实中我们通常面临的都是无限假设空间, 这是我们常用的工具就是假设空间的VC维.
我们先来讨论几个概念:
- 增长函数
对于假设$h$, 我们用它来对样本集赋予标记, 可以得到 随着$m$ 增大, 假设空间中所有假设对D中样本所能赋予的标记数的可能结果也会增加. 我们定义增长函数为: 也就是假设空间对样本集所能赋予标记的最大可能结果数. 增长函数能够体现假设空间的表达能力和复杂度, 有定理如下: - 打散
如果假设空间能够实现数据集上所有”对分”(我们称假设对数据集中数据赋予标记的每种可能结果称作对分), 对于二分类问题即为增长函数为$2^m$, 则称示例集能被假设空间打散.
下面就可以开始讨论VC维了,假设空间的VC维是能被$\mathcal{H}$打散的最大示例集的大小,即:
这里需要注意$VC(H)=d$表示存在大小为$d$的示例集能被打散,但不代表所有大小为d的示例集都能被打散. 可以看出VC维的定义和分布无关, 通常我们用大小为$d$的示例集能被打散, 而$d+1$的数据集不能来计算VC维.
那么显而易见的是VC维和增长函数应该会有密切的联系,有一个重要的引理, Sauer引理给出了二者之间的的定量关系(证明在西瓜书p275,数学归纳法, 还是比较漂亮的):
从而可以计算出增长函数的上界:
然后得到我们最终想要的基于VC维的泛化误差:
那么可以发现,任何VC维有限的假设空间都是(不可知)PAC可学习的.
这给出了在无限假设空间中学到满足经验风险最小化(ERM原则 Empirical Risk Minimization)的算法的理论保证, 而且VC维给出了我们在选择算法时的一种评价标准, 这里借用林轩田老师在机器学习基石里的一张图:
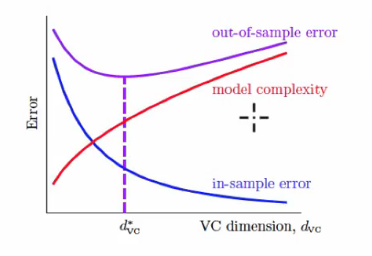
由于台湾和大陆术语上不太一致, 解释下这里的in-sample error就是经验误差, out-of sample error就是泛化误差. 可以发现, 不同VC维的算法, 如果VC维越高, 经验误差往往是能够持续下降的, 而模型复杂度也是上升的(很直观的看参数个数上升了嘛), 但是泛化误差会经历一个先下降后上升的过程, 其上升的过程即为我们熟知的过拟合. 那么, 如果能够从理论上分析出算法假设空间的VC维, 那就有助于我们设计和改进算法.
Rademacher 复杂度
之前提到基于VC维的泛化误差界是分布无关数据独立的,也就是说对任何数据分布都成立。 虽然这给VC维分析带来了普适性,但是这个往往会比较松。因此下面介绍一种考虑了数据分布的假设空间复杂度刻画方法。
这里不细谈了。
稳定性
这里算法稳定性考察的是算法在输入发生变化时,输出是否会随着发生变化。
我们在定义训练集的变化,$D$是来自分布$\mathcal{D}$的独立同分布采样数据集,对于假设空间$\mathcal{H}$,和学习算法$\mathfrak{L}$,令$\mathfrak{L}_ D\in \mathcal{H}$表示基于训练集从假设空间中学到的假设。 我们考虑以下的训练集变化:
- $D^{\backslash i}$表示移除第$i$个样本后的集合
- $D^i$表示替换第$i$个样本后的集合
接着我们定义以下损失函数:
泛化损失
经验损失
- 留一(leave-one-out)损失
接着定义算法的均匀稳定性:
定义 对任何 $x\in \mathcal{X}, z=(x,y)$,若学习算法$\mathfrak{L}$满足:
则成学习算法关于损失函数$\ell$满足$\beta-$均匀稳定性。
稳定性分析关注的是$| \widehat { \ell } ( \mathfrak { L } , D ) - \ell ( \mathfrak { L } , \mathcal { D } ) |$,而假设空间复杂度分析关心的是$\sup _ { h \in \mathcal { H } } | \widehat { E } ( h ) - E ( h ) |$.
稳定性和可学习性二者之间可以有下面的关系:
定理 若学习算法$\mathfrak{L}$是ERM且稳定的,则假设空间$\mathcal{H}$可学习。
这里的ERM指的是经验风险最小化(Empirical Risk Minimization),即学习算法输出的假设满足经验损失最小化。
 wechat
wechat alipay
alipay





