【西瓜书】第十三章 半监督学习
本文是周志华老师《机器学习》第十三章半监督学习的学习笔记及部分习题答案。
在实际应用中,有标签的数据的获取往往受成本限制,其数量是较小的;但是同时我们又有大量的无标签数据,如何同时应用小部分的有标签数据和数量上较多的无标签数据,这就是半监督学习研究的内容。
当然有了无标签数据我们也可以通过人力或者其他方法来赋予这些数据标签,但是这么做代价往往很大,因此主动学习应运而生,其核心思想是从无标签数据中挑出那些对改善模型性能帮助大的数据来打上标签,这样使用尽量少的“查询(query)”来获得尽量好的性能。
但是上述操作仍然是引入了额外的专家知识,半监督学习可以让学习器不依赖外界交互,自动的利用未标记样本来提升学习性能。
要利用这些未标记样本,需要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设,首先我们默认下面讨论都有一个前提,即未标记样本和标记样本是(近似)独立同分布的(不满足独立同分布情况的可以看作是某种意义上的迁移学习):
- 聚类假设 cluster assumption 假设数据存在簇结构,同一个簇的样本属于同一个类别。
- 流形假设 manifold assumption 假设数据分布在一个流形机构上,邻近的样本有相似的输出值。
半监督学习可以进一步分为两类:
- 纯(pure)半监督学习 假定训练数据中的未标记样本并非待预测的数据。
- 直推学习(transductive learning) 假定学习过程中所考虑的未标记样本恰好是待预测数据。
生成式方法
生成式方法(generative method)是直接基于生成式模型的方法,它假定所有数据都由一个潜在的模型生成出来。
那么未标记数据的标记可以看作是模型的缺失参数,通常可以基于EM算法进行极大似然估计求解。
以假设模型为混合高斯模型为例,给定样本$x$,其真实类别标记为$y\in \mathcal{Y}$,每个类别对应一个高斯混合成分,则有数据样本是基于如下概率密度生成的:
其中$\alpha$为混合系数, $\sum\alpha = 1$,$p(x|\mu,\Sigma)$为样本$x$属于第$i$个高斯仰恩混合成分的概率。
令$f(x)$表示模型$f$对$x$的预测标记,$\Theta$表示样本隶属的高斯混合成分,由MAP可得:
其中:
可以发现其中$p(y=j|\Theta=i,x)$需要有标记数据,而$p(\Theta=i|x)$不涉及样本标记,因此有标记和无标记数据均可以利用起来。
上面介绍了混合高斯模型的半监督预测,那么如何利用未标记数据来估计高斯混合模型的参数呢,这里可以用极大似然法。我们假设有标签数据集为$D_l$,无标签数据集为$D_u$,那么整个数据集的似然对数是:
该式的前一项对应有标记数据,后一项对应无标记数据。
接着可以用EM算法来求解。
类似的,我们将上面的高斯混合模型换成其他模型例如朴素贝叶斯等,即可以推导出其他的生成式半监督模型。
这类方法较为简单也易于实现,但是有一个关键:模型假设必须准确,否则利用未标记数据反而会降低泛化性能。
半监督SVM
半监督支持向量机(Semi-Supervised Support Vector Machine, S3VM)是支持向量机在半监督学习上的推广。它希望找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面。
在半监督支持向量机中,最著名的是TSVM,它考虑将每个未标记数据分别作为正例和反例,我们假设有标签数据集为$D_l$,无标签数据集为$D_u$,那么TSVM需要最小化的目标即为:
其中$w,b$确定了一个划分超平面,$\xi$为松弛向量,$C_l,C_u$是用户指定的用于平衡模型复杂度,有标记样本和无标记样本重要程度的折中参数。
当然,穷举式的去对未标记样本做标记指派复杂度是指数级别的,仅当未标记样本很少时才可行,因此TSVM使用局部搜索来迭代地寻找近似解:
- 先用有标记数据训练一个SVM
- 用得到的SVM来对未标记数据进行标记指派,将预测结果当作伪标记赋予未标记样本
- 用上述得到的数据带入上面的优化目标,得到一个标准SVM问题,求解出新的划分超平面和松弛变量,此时由于伪标记很可能不正确,因此$C_u$要小于$C_l$
- TSVM找出两个标记指派为异类且很可能错误的伪标记样本,交换其(伪)标记,再重新求解新的划分超平面和松弛向量,过程中逐步增大$C_u$
- 重复上一步直到$C_u=C_l$

当遇到类别不平衡的问题时,可以将上面的算法稍加改进,将优化目标中的$C_u$拆成$C^+_u$和$C^-_u$,分别对应基于伪样本而当作正反例使用的未标记样本,并在初始化时令:
图半监督学习
给定一个数据集,我们可以将其转换为一个图,每个样本对应一个点,样本之间的相似性(相关性)对应图中的边的强度,我们可以将有标记样本所对应的节点想象为染过色,而未标记样本就是未染色。那么半监督学习就相当于颜色在图上传播的过程。
我们可以将图的边集用一个亲和矩阵(affinity matrix)表示(这里基于高斯函数):
其中$\sigma \gt 0$是用户指定的高斯函数带宽参数。
假设我们从图中希望学到一个实值函数$f:V\rightarrow \mathbb{R}$, 然后用$y=\text{sign}(f(x))$来进行分类,接着就可以定于关于$f$的能量函数:
其中
前者为函数$f$在有标记样本上的预测结果,后者为在无标记样本上的结果,$D$为对角元素为矩阵$W$行之和的对角矩阵。
在有编辑样本上,具有最小能量的函数$f$有$f(x)=y$,在未标记样本上满足$\Delta f=0$,其中$\Delta = D - W$成为拉普拉斯矩阵。
将两类样本都分开,用分块矩阵的形式来表达优化目标(能量函数),并对$f_u$求导令其为零,可得:
这样我们就可以把标记信息作为$f_l$带入,并以对未标记样本进行预测。
多分类的标记传播
对于多分类的情况,类似的可以定义上述的$D,W$矩阵,同时我们可以定义一个样本矩阵并初始化为:
然后可以构造一个标记传播矩阵:
其中
并利用迭代公式计算:
直到收敛:
整个算法流程如下:

该算法对应正则式框架:
该式前一项迫使学习结果和真实标记尽可能相同,前一项则迫使相近的样本尽可能具有相似的标记。
图半监督学习的概念清晰,但是其空间复杂度较高,难以直接处理大规模数据。另外在新样本的处理上也较为低效。
基于分歧的方法
基于分歧的方法(disagreement-based methods)使用多学习器之间的分歧来利用未标记数据。
基于分歧的方法的代表是协同训练,在介绍它之间我们先来介绍几个概念:
- 多视图数据 数据对象往往有多个属性集,每个属性集构成一个视图,例如对电影数据来说,可有基于图像的视图和基于音频的视图。
- 相容性 不同视图关于输出空间的信息一直的信息,例如从视频上来看某部电影的输出标签为标签集{爱情片,动作片}之一,从音频上来看,对应的标签集也得是这个。
- 互补性 不同视图的信息如果结合起来能够提高学习器性能,例如从画面上来讲,二人对视的画面信息如法判断内容,但是如果声音信息中含有例如“我爱你”,那么二者互补就容易判断出是爱情片。
协同训练正是利用了多视图的相容互补性,它假设数据有两个充分且条件独立视图。充分是指每个试图都包含足以产生最优学习器的信息,条件独立指在给定类别标记的条件下两个视图相互独立。接着就用下面的方法来利用伪标记数据:
- 在每个数据视图上分别训练一个分类器,然后让每个分类器分别去挑选自己最有把握的未标记样本赋予伪标记。
- 将未标记样本提供给另一个分类器作为新增的有标记样本用于训练更新。
- 重复上述两步直到两个分类器都不再发生变化。
虽然过程简单,但是理论证明表示,如果两个视图充分且条件独立,则可以利用未标记样本通过协同训练将弱分类器的泛化性能提升到任意高。
后来的研究指出,该算法改动后也可以用在单视图上,只要弱学习器之间有显著的差异。
半监督聚类
聚类本身是一种典型的无监督学习任务,但是我们现实任务中往往可以利用一些额外的信息来帮助其获得更好的聚类效果。
监督信息可以化为两类,一种是必连(must-link)和勿连(cannot-link)限制,还有一类监督信息可以是少量的标记样本(不过这类信息也可以转化成必连和勿连关系)。
pair-wise限制信息
约束k均值算法就是一种利用上述监督信息的聚类算法,具体算法描述如下:

类别标记信息
第二类信息是少量标记样本,这种信息其实可以转化为前一种限制信息处理,第二种方法更容易,直接将它们作为种子,利用它们初始化k均值算法的k个聚类中心,并在聚类簇的迭代过程中不改变种子样本的簇隶属关系,算法描述如下:

习题与参考答案
1. 试推导出式(13.5)~(13.8)

2. 试基于朴素贝叶斯模型推导出生成式半监督学习算法
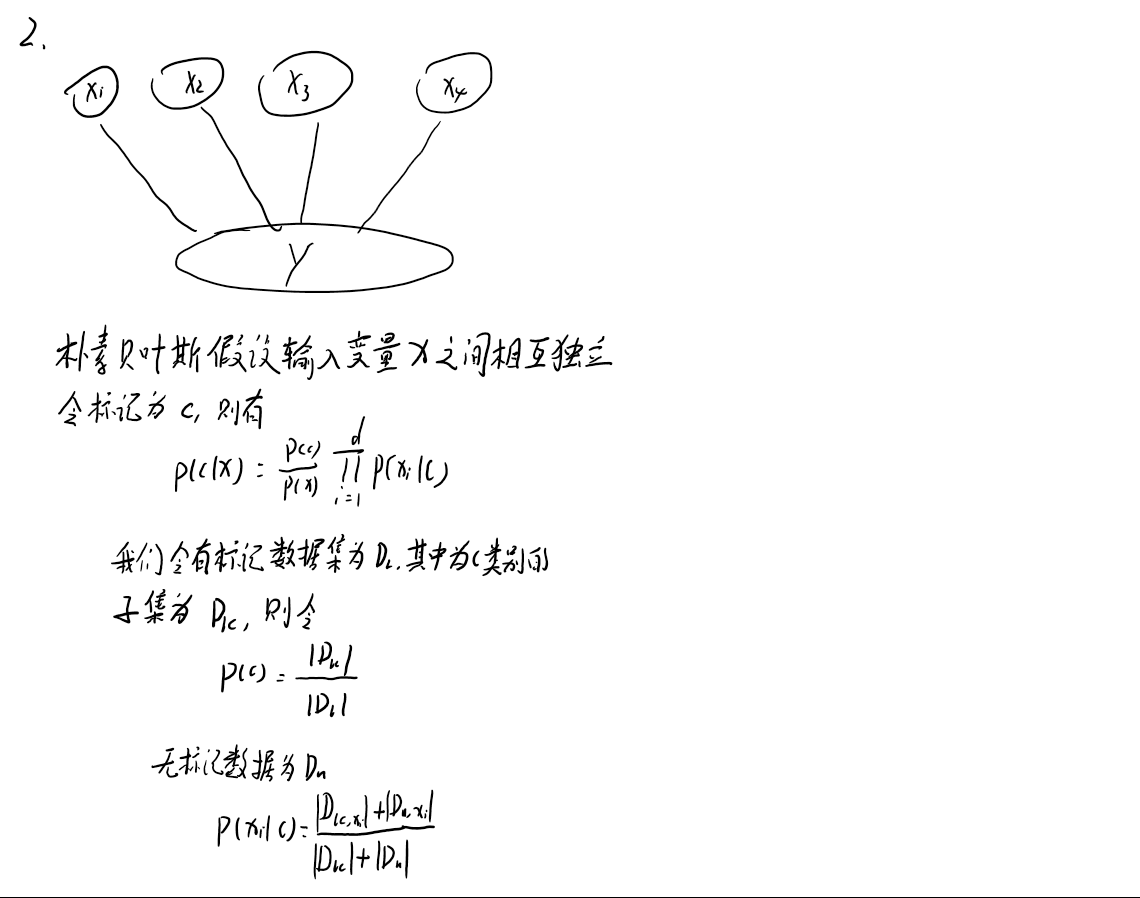
除此之外还有一种自训练方法,即用带标签数据训练得到无标记数据的类别概率,并用概率值这种“软标签”作为其伪标记,然后在有标记和伪标记数据上重新训练。
3. 假设数据由混合专家(mixture of experts)模型生成,即数据是基于$k$个成分混合而得到的概率密度生成:
试推导相应的生成式半监督学习算法。
4. 从网上下载或者自编程实现TSVM算法,选择两个UCI数据集,将其中30%的样例用错测试样本,10%的样例用作有标记样本,60%的样例用作无标记样本,分别训练出利用五标记样本的TSVM以及仅利用有标记样本的SVM,并比较其性能。
可以参考这里.
5. TSVM对未标记样本进行标记指派和调整的过程中有可能会出现类别不平衡的问题,是给出考虑该问题后的改进TSVM算法。
p209已经给出了解决方案。
6. TSVM对未标记样本进行标记指派和调整的过程涉及很大的计算开销,试设计一个高效的改进算法。
这里由于每一轮标记指派调整只改动两个样本的标记,因此还需要很多轮指派直到满足条件。因此可以在调整早期调大改动标记的样本的数目,并在过程中不断减少这个数目直到最后满足条件。思想类似于梯度下降中的动量法(momentum)。
7. 试设计一个能对新样本进行分类的图半监督学习方法。
略。
8. 自训练(self-training)是一种比较原始的半监督学习方法:它先在有标记样本上训练,然后用学得的分类器对未标记样本进行判断别以获得其伪标记,在在有标记和伪标记样本的合计上重新训练,如此反复。试析该方法有何缺陷。
有标记样本较少时,学习出来的分类器性能会很弱,那么后来赋予无标记样本的伪标记中错误就会较多,最后重复训练的学习器会有很大程度上是在拟合数据噪声。
9. 给定一个数据集,假设其属性集包含两个视图,但事先并不知道哪些属性属于哪个视图,试设计一个算法将这两个视图分离出来。
想到两种方法:
- 通过某种度量来算两种属性之间的相似度(比如利用概率图模型来推断),然后得到pair-wise关系,然后可以适当构建二分图。
- 将属性的各个样本上的标记作为属性的特征,然后聚类。
10. 试为图13.7算法的第十行写出违约检测算法。
对于每个目标样本:
- 对于其Must-link的样本,如果这些样本不在分配给目标样本的簇中,返回False
- 对于其Cannot-link的样本,如果这些样本有在分配给目标样本的簇中,返回False
- 以上两条都满足了,返回True
 wechat
wechat alipay
alipay





